

DBoW2
안내글
본 포스트에서는 DBoW2 라이브러리에 대한 사용을 위한 논문인 “Bags of Binary Words for Fast Place Recognition in Image Sequences”의 논문 리뷰를 진행합니다. 이전 포스터에 이어서 계속됩니다.
제안방법
: 논문에서 ORB 키포인트를 추출하는 부분의 설명은 생략하겠습니다.
이미지 데이터베이스
이전에 방문했던 장소를 인식하기 위해서, 논문에서는 계층적인 bag of word로 구성된 이미지 데이터베이스와 direct index, inverse index를 사용합니다.
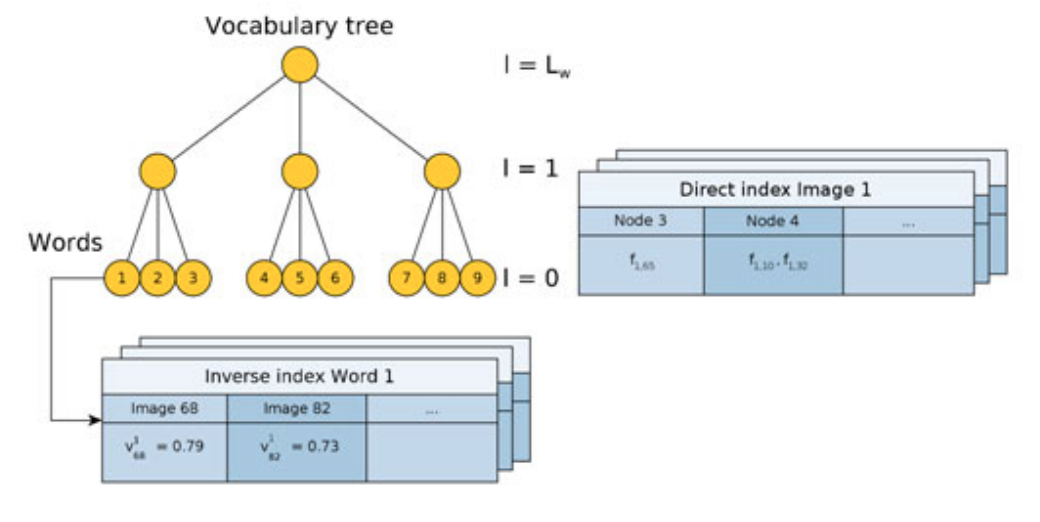
Figure 1 . Vocabulary word는 Tree의 leaf node이고, inverse index는 이미지들에 대해서 word별 가중치 정보를 가지고 있다. (한 이미지에서 존재하는 word의 비율) direct index는 이미지별로 tree의 한 레벨에서 노드별로 포함하는 특징점을 구분하고있다.
계층적인 bag of word는 이미지의 특징점에 대한 vocabulary1를 Figure 1과 같이 tree구조로 생성합니다. 이를 위해서 우선 훈련이미지들로부터 많은 특징점을 추출합니다.
그리고 이 특징점(feature, descriptor의 의미)들은 K-Means ++ seeding 기반의 K-Median clusting을 수행함으로써 $k_w$ 개의 이진 군집들(clusters)으로 분할됩니다. (이 과정에서 이진이 아닌 값은 0으로 바뀝니다.) 이 군집들은 vocabulary tree에서 첫번째 레벨 (l=0)의 노드들을 형성합니다. 나머지 상위 레벨 노드들은 이러한 연산을 각 노드(군집)에 대응되는 descriptor들에 대해서 이 연산을 $L_w$번까지 반복 실행합니다.(다시 군집화 연산을 한다는 뜻입니다.) 최종적으로 W개의 leaf를 가진 tree를 생성되고, tree 구조내에 leaf는 vocabulary의 word를 나타냅니다. 이러한 word에 대해서는 훈련 말뭉치(training corpus)와 관련된 가중치가 붙게 됩니다. 이 가중치는 자주 등장할수록 가중치가 낮은, 구분하는 성능이 낮은 특성을 가지며, tf-idf2로 계산됩니다.이미지 한장이 주어지면, t 시간에 하나의 bag of word vector $v_t \in R^W$로 표현됩니다. 이때 각 특징점들은 tree로 내려가면서, 노드중에서 이것의 hamming distance를 작게하는 노드를 선택하며 특정 leaf(word)가 선택됩니다.
2개의 bag of word vector $v_1,v_2$ 사이의 유사도를 측정하기 위해서, 논문에서는 $L_{1}-score$ $s(v_1,v_2)$를 사용합니다.
$s(v_1,v_2) = 1-\frac{1}{2}\left\lvert \frac{v_1}{\lvert v_1 \rvert} -\frac{v_2}{\lvert v_2 \rvert}\right\rvert$
이 과정에서 inverse index가 생성이 됩니다. 이 구조는 vocabulary에 있는 각 word $w_i$에 대해서 각 word를 가지고 있는 이미지들을 저장합니다. 이러한 방식은 데이터베이스에서 query 이미지와 유사한 이미지를 찾을 때, 비슷한 word를 가지고 있는 이미지들을 찾을 때 편리합니다. 이 inverse index는 이미지에서 해당 단어의 가중치를 얻기위해서 $<I_t,v^i_t>$의 형태로 저장합니다. inverse index는 새로운 이미지가 데이터베이스에 추가될 때마다 업데이트되고, 데이터베이스가 몇가지 이미지에 대해서 검색될 때 접근됩니다.
이 논문에서는 추가로 direct index를 사용하였습니다. 이것은 각 이미지의 특징점을 편하게 저장하기 위해서 사용됩니다. 논문에서는 tree 구조내 각 층(level)마다 노드로 나눠두었는데, 각 이미지 $I_t$에서 특정 level $l$ 의 노드들과 각 노드 별로 포함하는 특징점의 종류와 수를 direct index에 기록해두었습니다. 이러한 방식은 이미지 사이에 descriptor에서 neariest neighbor를 찾을 때 사용하기 위해서 채택하였습니다. 결과적으로 추후에 설명될 논문의 기하학적 검증(geometry verification)의 속도를 향상시켰습니다. (이 검증 간에 오직 같은 특징점에 속하는 단어나 같은 level $l$의 node에 속하는 특징점 사이에만 유사성을 비교합니다.) direct index는 새로운 이미지가 데이터베이스에 추가 될 때 업데이트되고, 새로운 매칭이 얻어지고 geometry verification이 필요할 때 접근됩니다.
논문리뷰의 나머지부분은 DBow2 논문 리뷰 및 기반의 위치 인식 프로그램 제작(3)에서 계속됩니다.
[1]vocabulary : 이미지 내에 존재한 특징점들은 정해진 갯수의 대표 feature들로 분류할 수 있다. 이러한 대표 특징점들을 word라고하며, 이러한 word의 모임을 vocabulary라고한다.
[2]tf-idf : (하나의 이미지 내에 등장하는 word의 빈도)/(전체 데이터 내에서 해당 word가 등장하는 이미지의 빈도 수)